Nvidia's DLSS carbon impacts: the cost-benefit of upscaling, frame generation, and neutral network training


Late last year I got a new graphics card for my PC – a rather modest new Nvidia RTX 4060 which is pretty much perfect for the games I play. It’s a mid-tier card, but still a huge upgrade (now approaching 7 years old) GTX 1070 that I had been rocking for a long, long time. I think the 1070 was a fairly power-hungry card (though I haven’t tested – yet!). It needed one 6-pin and an 8-pin power connector to run, and it got quite warm. Its TDP (Thermal Design Power – a rating of how much heat it is expected to produce and needs to dissipate) was rated at 150 watts, with a suggested minimum power supply of 450 watts (according to this GPU comparison site anyway). By contrast, my new RTX 4060 has a TDP of 115 watts, uses only one 8-pin power connector, and has a minimum recommended PSU of just 300 watts. So a TDP reduction of 35 watts translates into fitting within a 150 watt less capable power supply.
The difference in performance though is night and day – this comparative chart (from the same site) is pretty indicative of what I have noticed so far.

I’ve long been curious about the real-world application of Nvidia’s DLSS system of resolution scaling, frame generation, and other “AI-powered” graphical features. Now I'm an AI sceptic, and I think it’s worth retaining a healthy distrust of the more exceptional claims attached to the (unhelpfully broad) term "AI". But even I have to be honest that once I plugged my PC into my gorgeous 4K TV, I was seriously impressed by the results.
Even at 1080p, my old card would average around 25-30FPS in Baldur’s Gate 3. meaning that it was playable, but hardly a pleasure. It also struggled with some of the bigger scenes towards the end of the game, and that was without many of the visual bells and whistles turned down too. This new card? Even with everything set to high, even some ultra, I’m probably averaging around 50+ FPS in 4K. How can that be possible!?
Now remember: 4K is quadruple the number of pixels on screen compared to 1080p, and this card is supposedly only 1.6x more powerful. So what’s the secret under the hood? It’s got to be DLSS and all the fancy math behind it. I can feel myself becoming a convert to this AI graphics stuff at least, and I think it might have some important implications for energy use and emissions in games.
From what I’ve been able to read so far, DLSS works by rendering an image at a lower resolution than the output resolution (in my BG3 example, I have it set to “quality” so it renders around 75% of the full 4K image) and then uses the AI model to “interpret” what the remaining pixels of the image should be. So it’s filling in maybe a quarter of the pixels by (AI-powered) guessing, rather than following a complicated rendering pipeline to actually compute each and every individual pixel value.
But there are other tricks it’s doing too – including (if it’s running DLSS 3.5) generating in-between frames. Again, it’s handing over image generation for one frame to an AI, making inferences on what the next frame should be based on the previous frame and a bunch of 3D parameters fed in by the engine, such as edges and movement and so on. If it works, it can double the number of frames you get, for not much extra work on the GPU. I think a lot of the extra performance I’m getting out of this new card (that is only 1.6x better than my old one) is based on AI.
Okay, that’s all well and good, but what are the implications from an energy and emissions perspective? Well at first I was a little bit concerned that it might just be shifting the emissions from the end-user phase to the training of the DLSS AI itself. We’ve been seeing more and more stories about the resource and energy intensity of training AI processes (particularly cloud-based ones, and LLMs like ChatGPT). But I went looking for some answers about whether or not the same applies to the DLSS training, and while I’m only at the very start of thinking through this, quietly I’ve gotten a little bit excited by what I think it suggests.
Perhaps unsurprisingly, Nvidia is pretty tight-lipped about the development of DLSS. It’s quite commercially sensitive, as it’s a big advantage over ATI which seems to still be catching up in this specific area, but I have found some info about how DLSS was trained, mainly from the marketing and promotional materials from the past few years. I first found this 2018 developer blog with a bit of Q&A about the training process for the first iteration. It’s a long quote, but it’s worth reading:
The DLSS model is trained on a mix of final rendered frames and intermediate buffers taken from a game’s rendering pipeline. We do a large amount of preprocessing to prepare the data to be fed into the training process on NVIDIA’s Saturn V DGX-based supercomputing cluster. One of the key elements of the preprocessing is to accumulate the frames so to generate “perfect frames”.
During training, the DLSS model is fed thousands of aliased input frames and its output is judged against the “perfect” accumulated frames. This has the effect of teaching the model how to infer a 64 sample per pixel supersampled image from a 1 sample per pixel input frame. This is quite a feat! We are able to use the newly inferred information about the image to apply extremely high quality “ultra AA” and increase the frame size to achieve a higher display resolution.
To explain a little further, DLSS uses a convolutional auto-encoder to process each frame which is a very different approach than other antialiasing techniques. The “encoder” of the DLSS model extracts multidimensional features from each frame to determine what are edges and shapes and what should and should not be adjusted. The “decoder” then brings the multidimensional features back to the more simple Red, Green, Blue values that we humans can understand. But while the decoder is doing this, it’s also smoothing out edges and sharpening areas of detail that the encoder flagged as important.
So there’s a few clues here about the training process and its (potential) energy use. First, at this point in 2018, DLSS still had to be trained on a per-game basis (which I’ve seen verified elsewhere), and it involved training on “thousands” of highly anti-aliased images output through the game engine itself. To me that suggests perhaps only a moderately intensive process for a few machines to produce – but it’s not millions of images. They are being highly anti-aliased, and while that’s too slow of a process to be done in real time, taking a lot of computing power to crunch, at a guess I’d say we’re maybe talking hours of work not weeks or more? The slowest part of it is probably getting the engine setup to produce the outputs DLSS training required – which, if it took a few weeks, might end up beating the energy consumed by the training itself (which we’ll get to in a minute).
“Traditional” AA methods (going back to the late 90s and early 00s) are still suuuuper slow because for each frame you have to compare every single pixel with every adjacent pixel. The amount of pixel comparisons they’re talking about here are 64 per pixel. A 1080p image is already made up of 2 million pixels – so you’re doing 128 million pixel comparisons to antialias your image (unless I’m misunderstanding something about the process). And they’re also doing this for 4K (and later, potentially, 8K as well) images 1,024 million pixel comparisons per highly anti-aliased image. So it’s not exactly a walk in the park to do these super-anti-aliasing passes of rendered output, and you’ve got to do that a few thousand times for your game. But this all still sounds doable by a couple of engineers and a couple of machines over maybe a few days?
Once you’ve got your training images, and your engine states that go with them, then you can train the DLSS AI process on the Saturn V DGX-supercomputer cluster. Could that be more power intensive (and by extensions, higher emissions) than the rendering? Actually, I don’t think so. Here’s a slide from a 2019 marketing PDF for the early DGX-1 and DGX-2 computing clusters with some clues.
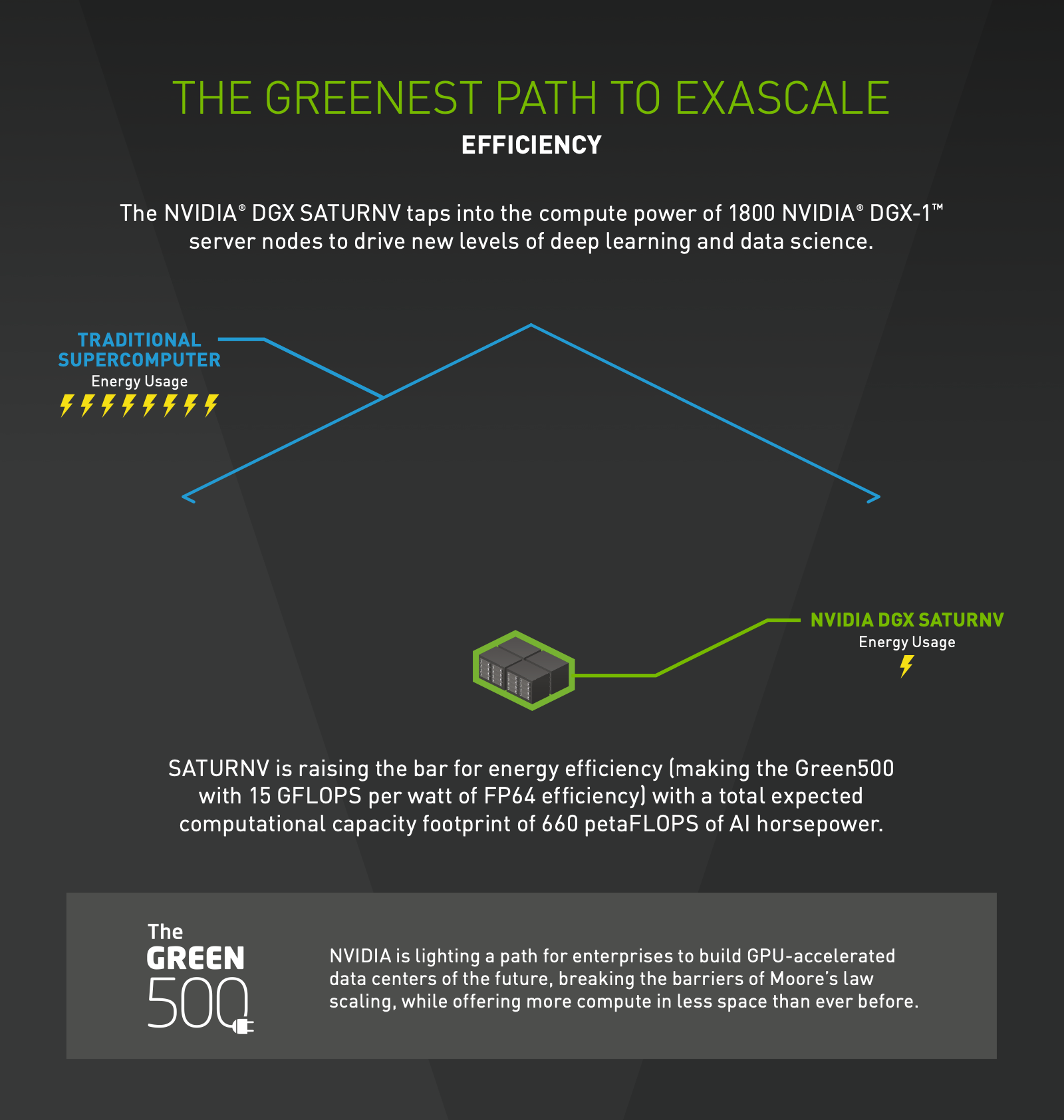
This the most revelant bit:
SATURNV is raising the bar for energy efficiency (making the Green500 with 15 GFLOPS per watt of FP64 efficiency) with a total expected computational capacity footprint of 660 petaFLOPS of AI horsepower.
Even taking this with a grain of salt (it is marketing material after all) that still sounds pretty impressively efficient. 15 gigaflops per watt is… insane? Am I crazy in thinking that sounds too good to be true? I’m well outside my comfort zone here, so if you know better, or can even conformations that, yes, that’s actually what it can do, all comments are gratefully received.
I asked my friend A/Prof Mark Nelson, game & AI researcher in the Dept of Computer Science at the American University, in Washington DC, for his best guesses about the size of energy consumed in training for DLSS. He told me that,
“My guess would be that the training time & power is quite small, because these models are tiny (esp. compared to say large language models), and training time is usually about proportional to model size, though that isn't a hard-and-fast law.”
Looking at the examples of other AI training examples the same marketing PDF shows would seem to back up what Mark says. Their training examples (even in 2019!) are in the minutes, not in the weeks or months like some LLMs.
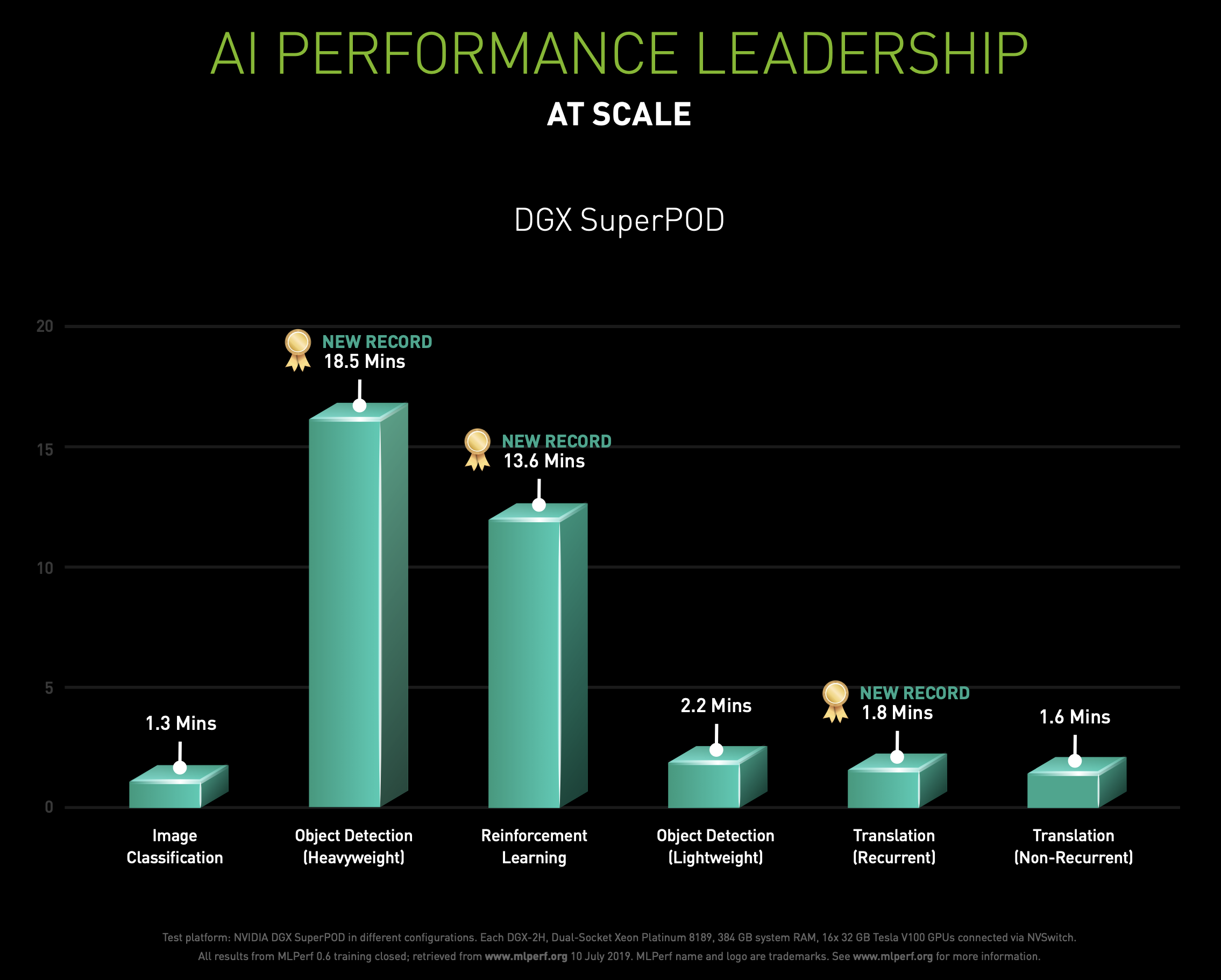
So the DLSS training process when it was on a per-game basis might have been a bit involved – but it sounds like the hardest/most computationally intensive part is gathering the “thousands” of high-quality images to feed into the model, rather than training the DLSS model on those images themselves.
The capabilities of DLSS has also come a long way since 2018, adding a ton of new AI features that can be run in real-time in addition to resolution upscaling. The current version is DLSS 3.5, which added in the ability to generate in-between frames (potentially doubling the effective FPS, if it’s fast enough?) and added an AI-powered “ray reconstruction” which does something with ray-tracing as well? Not as clear on the last one, or why anyone would want to use ray tracing anyway, but hey the frame generation and scaling stuff works a treat.
{kind=link}
Here’s how an Nvidia post describes the latest version launched mid-last year, with some more details on the training of the latest version as well:
“Trained using offline-rendered images, which require far more computational power than can be delivered during a real-time game, Ray Reconstruction recognizes lighting patterns from training data, such as that of global illumination or ambient occlusion, and recreates it in-game as you play…. Thanks to RTX, you effectively have the power of 2 computers in your PC or laptop - the first, an NVIDIA supercomputer that trains the DLSS AI model with billions of data points, to boost performance and image quality. And the second, your GeForce RTX graphics card, with dedicated tensor cores to execute the AI model in real-time, plus specialized RT Cores, innovations such as Shader Execution Reordering, and the raw power of each RTX GPU, delivering best-in-class ray tracing.”
I’m not much of a fan of that analogy of “the power of 2 computers” – I don't think it captures what's going on here, and it's not how I would describe it, but sure, fine. Marketers gonna market. Those GPUs won’t sell themselves I suppose. Unless they do.
I’ve seen it mentioned in press reports from around the same time that the amount of training data that went into this latest iteration was around 5x what was used in previous ones – which still doesn’t suggest anything even close to the scale being approached by some of the other super huge AIs models. And that’s good! It means we’re not just burning up huge GPU cycles in supercomputer clusters to get a few extra frames in our games. A little bit of training seems to unlock a lot of extra power for end users, and it’s not clear (to me at least) that it would use any more energy than traditionally computing all those pixels. In this case, the faster AI techniques probably do save power – at least, relative to an older generation of graphics architecture. Achieving higher efficiency is already crucial in lowering energy consumption and emissions, as many organisations (like the IEA) have pointed out.
It also seems to suggest that, if there are further AI graphics process developments that can save on end-user power consumption (as DLSS seems to, by enabling higher performance with a lower footprint) then it’s almost certainly worth doing.
Now the part of this that I haven’t touched on at all, however, is whether the greater efficiency of new cards is sufficient to offset the carbon used to produce them. Especially if your old GTX 1070 is just going to head to landfill, become e-waste, etc. A seven-year lifespan for a GPU is already pretty impressive, however, and things do need replacing eventually. We're going to have to park this question for now though.
There’s also the challenge that a fixed hardware energy profile presents, largely “locking in” a certain maximum power consumption over the lifespan of the hardware. And while there have been some great strides made in the past 12-18 months to find ‘efficiency’ at run time, there may very well come a day when achieving net zero is going to mean making more difficult choices. If over an 8-hour gaming session you spend only 45 minutes on menu screens with optimised energy use then we have still not addressed the bulk of end–user consumption (and by implication, emissions).
Will gamers be willing to accept more comprehensively AI-powered graphics that achieve “good enough” visual fidelity if it doesn’t make use of the full capacity of their hardware? Or are they going to feel like they’ve left “performance on the table” based on their expensive GPU and its full capabilities? I’ll leave you to decide that one.